
据财联社报道,周三,美国一家律师事务所向加州北区联邦法院提起集体诉讼,指控OpenAI和微软使用互联网抓取的信息来训练ChatGPT时,严重侵犯了无数人的版权和隐私,要求公司赔偿30亿美元。
其在诉状中指出,尽管制定了购买和使用个人信息的协议,但被告采取了不同的方式:盗窃。OpenAI和微软系统性地从互联网中窃取了3000亿个单词,包括数百万未经同意获取的个人信息。其中,账户信息、姓名、联系方式、支付信息、聊天记录等隐私数据都在未经许可的情况下,被OpenAI和微软收集、存储、共享和披露。
目前已有16名人士列席原告,Clarkson律师事务所还在寻找更多的原告。此外,Gunderson Dettmer事务所的知识产权律师分析,艺术家和其它创意专业人士若证明他们受版权保护的作品被用来训练人工智能模型,或许可以对人工智能公司提起异议,但仅仅在网站上发帖或评论的人,不太可能用版权保护来获得赔偿。
最新动态
-

有潜力的稀土永磁龙头股有哪些(3/9)
2023-03-10
-

中国科技馆将推出“非遗科普周”活动
2023-06-06
-
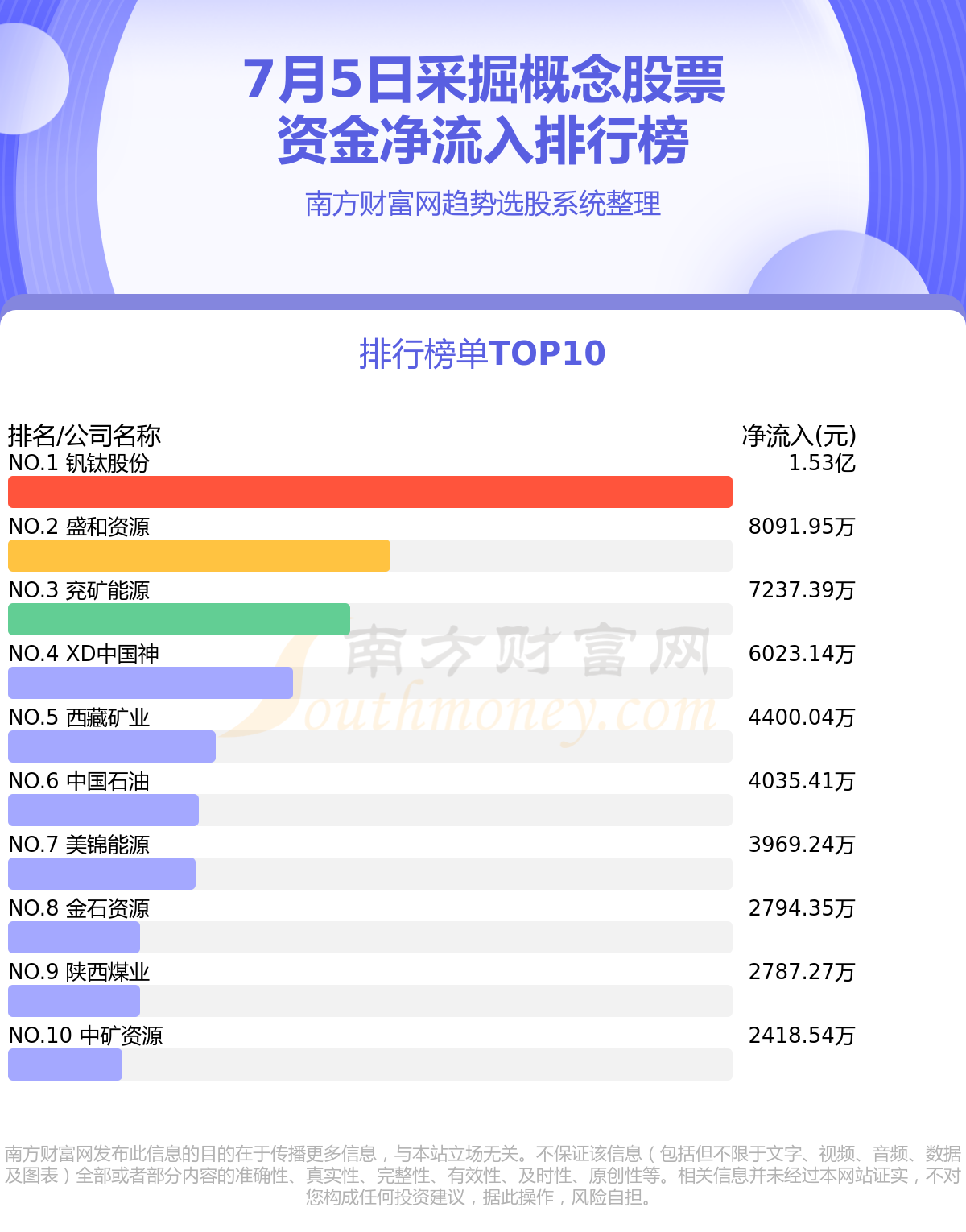
7月5日采掘概念股票行情及资金流向查询
2023-07-06
-
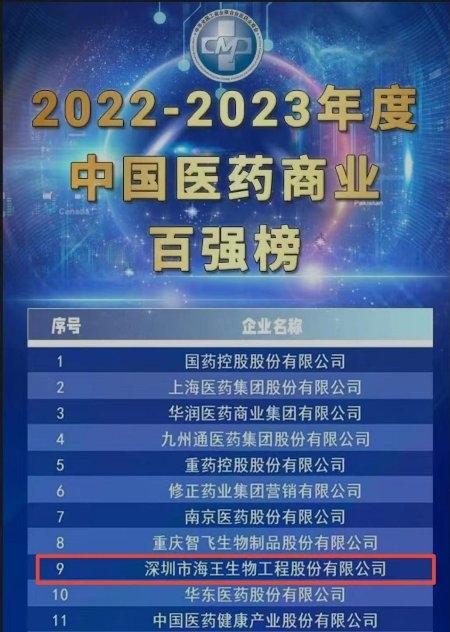
坚持稳基础 抓落实 求创新 海王生物连续3年上榜中国医药商业十强
2023-07-13
-

2023年高端装备股票的龙头股是哪只股?(2月17日)
2023-02-17
-

六一儿童节,一起到中科馆体验科学乐趣!
2023-05-31
-
玩家投票《最终幻想16》新实机 近9成玩家给出好评召唤兽奇幻游戏单人游戏动作游戏
2023-04-14
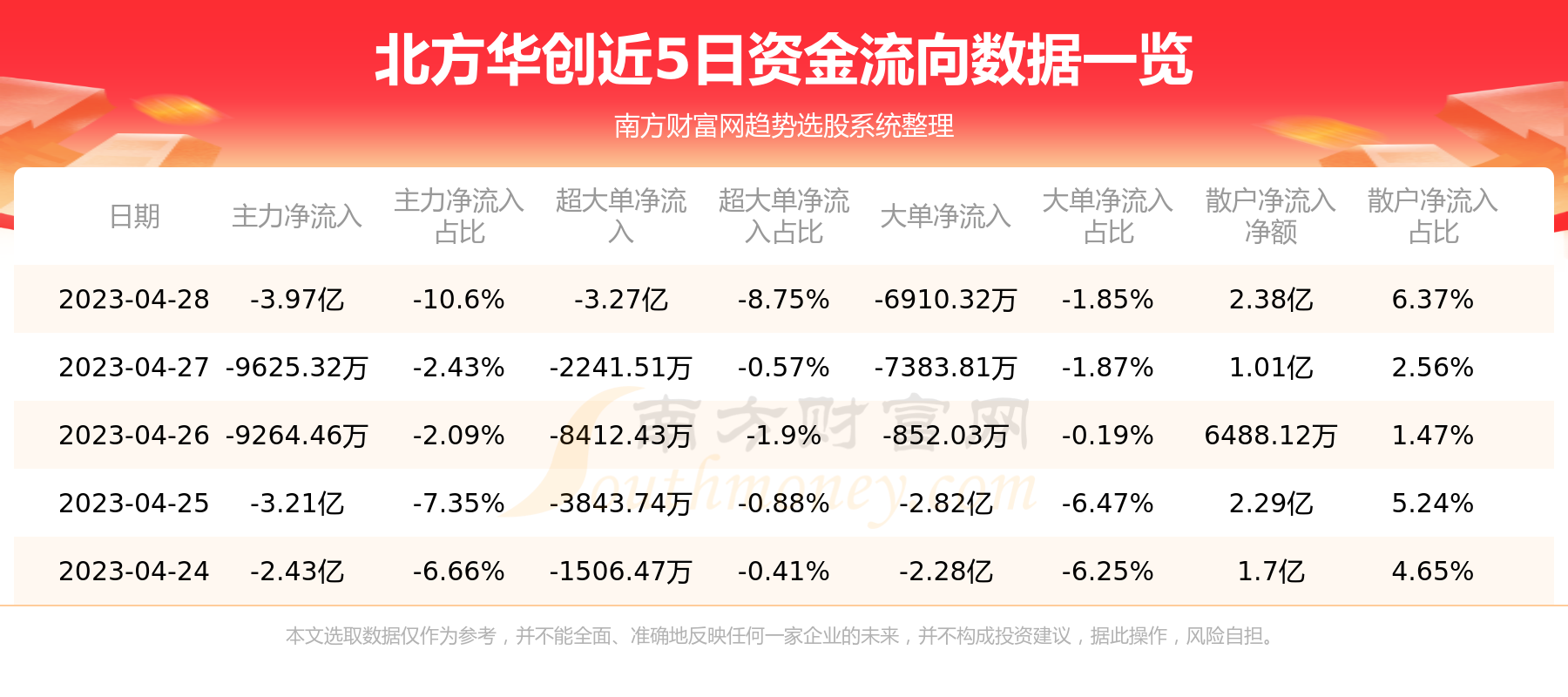
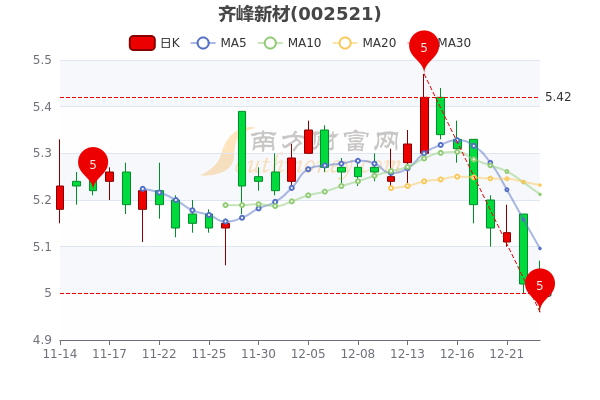

.jpg)